Overview
Bloom filter is Probabilistic data struct, it can tell an object is definitely not exist in the set or problably exist in the set.
Means when it tells false, it is the 100% correct, and when it tells true it's not 100%, there's a chance that element doesn't exist in the set.
It's just a filter, and doesn't store actual objects.
So for sets of large number of elements, there's huge performance different between a hash table and a Bloom filter.
The following figure describes how to add an element.
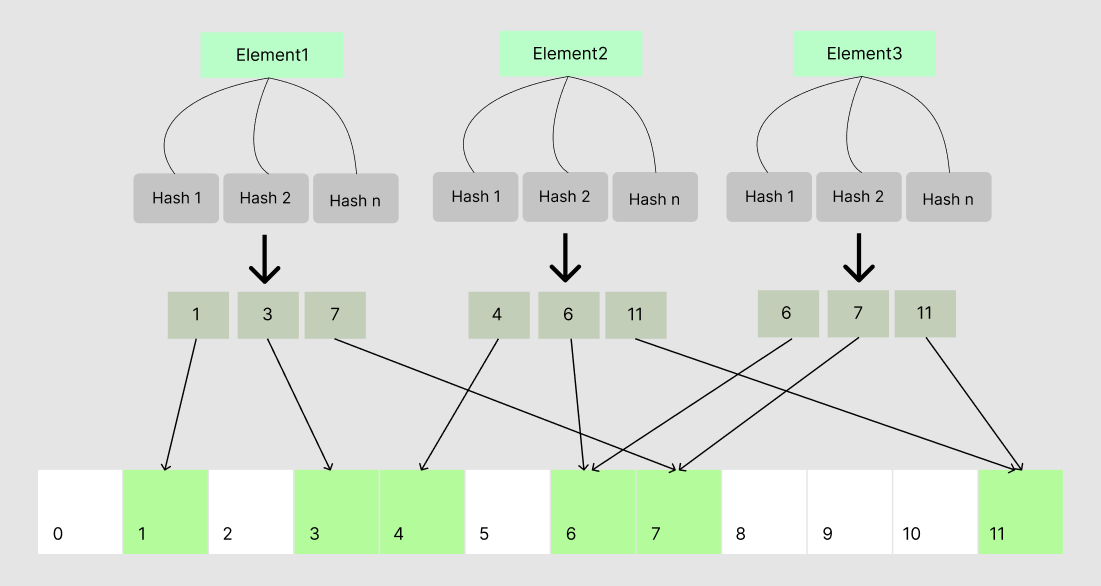
A Bloom Filter contains set of Hash functions and a bit array to store results.
- When inserting an element, we compute all hashes and turn on the certain bit.
- When checking existence of an element, we also compute all hashes by hash functions above. Hash results will be used to pick the status of bits.
If any bit is not turned on, the element does not exist.
If all bits are turned on, we can tell the element might exist.
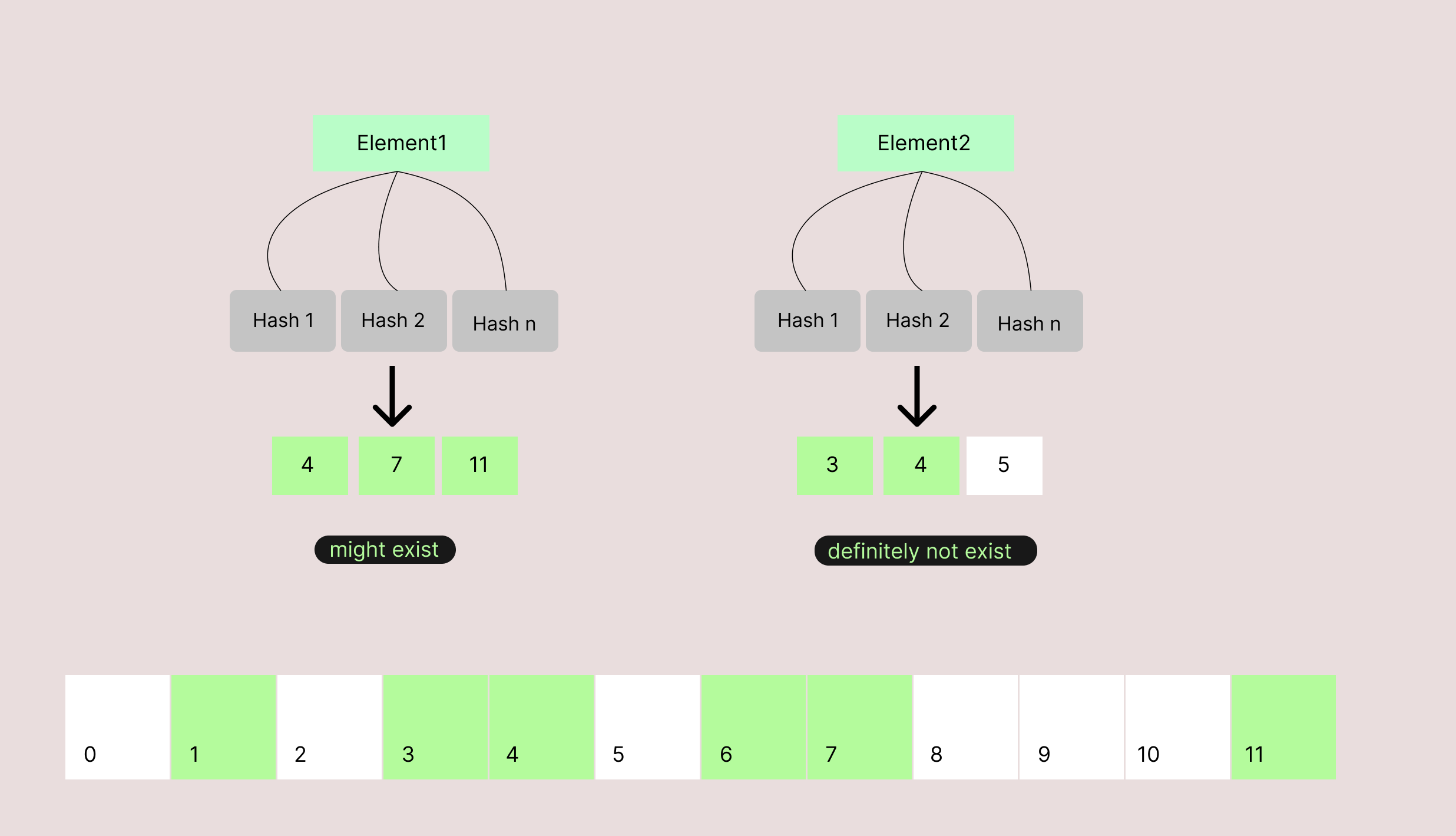
It's easily to figure that bloom filter cannot support deletetion, if we turn off any bit it may affects existence of many elements.
Implementation
Here is simple implementation. We support three methods for our Bloom Filter: insert, filter, and isEmpty
class BloomFilter<T> {
private var array: [Bool]
private var hashes: [(T) -> Int]
init(size: Int = 1024, hashes: [(T) -> Int]) {
self.array = [Bool](repeating: false, count: size)
self.hashes = hashes
}
private func computeHashes(_ value: T) -> [Int] {
return hashes.map { hash in abs(hash(value) % array.count) }
}
}
extension BloomFilter {
func insert(_ element: T) {
for hashValue in computeHashes(element) {
array[hashValue] = true
}
}
func filter(_ value: T) -> Bool {
return computeHashes(value)
.map { hashValue in array[hashValue] }
.reduce(true, { $0 && $1 })
}
func isEmpty() -> Bool {
return array.reduce(true) { prev, next in prev && !next }
}
}
Hash functions
There's a swift evolution about hash functions.
https://github.com/apple/swift-evolution/blob/master/proposals/0206-hashable-enhancements.md
Hashable protocol was changed from property hashValue:Int to additional hashInto(hasher: Hasher) function
Swift 1.0
struct GridPoint {
var x: Int
var y: Int
}
extension GridPoint: Hashable {
var hashValue: Int {
return x.hashValue ^ y.hashValue &* 16777619
}
static func == (lhs: GridPoint, rhs: GridPoint) -> Bool {
return lhs.x == rhs.x && lhs.y == rhs.y
}
}
Swift 4.1~
extension GridPoint: Hashable {
func hash(into hasher: inout Hasher) {
hasher.combine(x)
hasher.combine(y)
}
}
We can take advantage of this Hasher to implement Hash functions for our Bloom filter by providing a feed value for each hash. Under the hood of Hasher is SipHash.
func hash(_ valueToHash: T) -> Int where T is Hashable {
var hasher = Hasher()
hasher.combine(nthFunctionFeedValue)
hasher.combine(valueToHash)
return hasher.finalize()
}
There's also other hash function like naive or djb2
func naiveHash(_ string: String) -> Int {
let unicodeScalars = string.unicodeScalars.map { Int($0.value) }
return unicodeScalars.reduce(0, +)
}
func djb2Hash(_ string: String) -> Int {
let unicodeScalars = string.unicodeScalars.map { $0.value }
return unicodeScalars.reduce(5381) {
($0 << 5) &+ $0 &+ Int($1)
}
}